今年の5月に『Rによるインタラクティブなデータビジュアライゼーション』という本を出しました。

この本は、主に plotly パッケージを使ってインタラクティブなグラフを作成するためのノウハウについて書かれています。
一方、この本にはビジュアライゼーションのちょっとした小技やテクニックが所々に散りばめられていて非常に勉強になります。
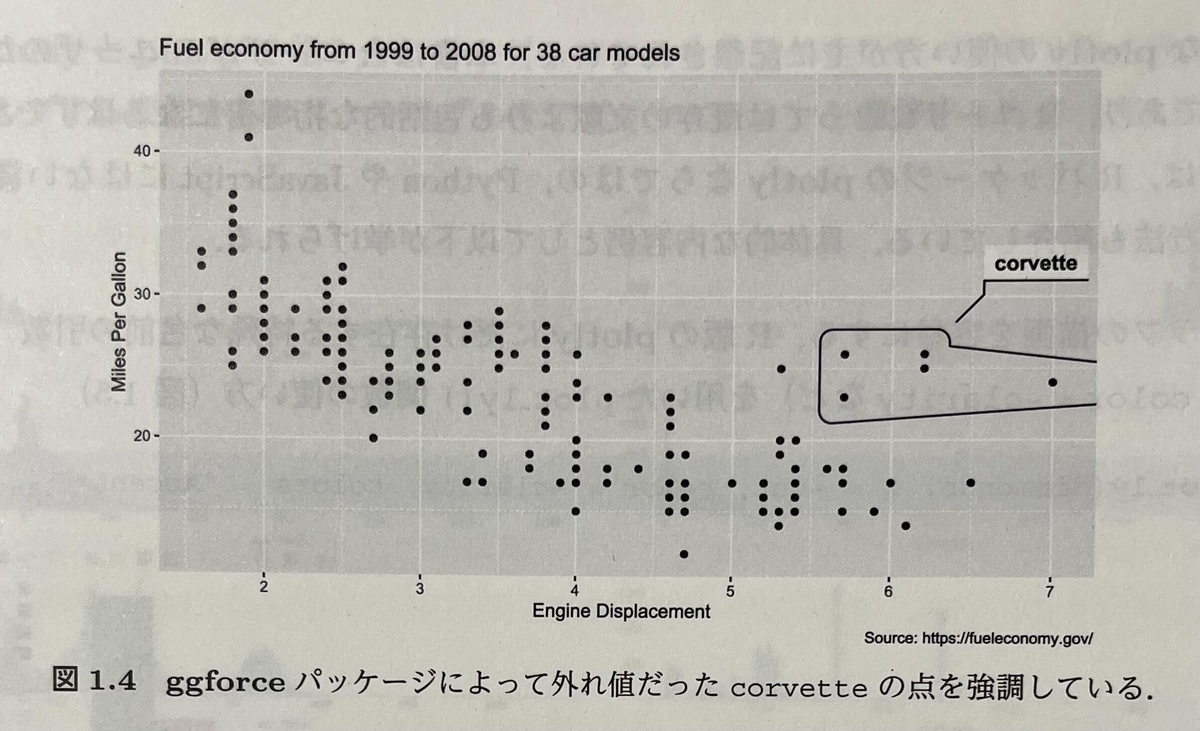
例えば、第1章には、外れ値を強調するために ggforce パッケージの geom_mark_hull() という関数を使う例が載っています。
ggforce パッケージには、この類似機能として以下の4つの関数が含まれています。
geom_mark_rect()geom_mark_circle()geom_mark_ellipse()geom_mark_hull()
これらの関数は使ってみるとめっちゃ便利です。 今回はこれらの関数について紹介したいと思います。
まずはパッケージの読み込みと使うデータ (iris) の確認をします。
library(ggplot2) library(ggforce) head(iris)
Sepal.Length Sepal.Width Petal.Length Petal.Width Species 1 5.1 3.5 1.4 0.2 setosa 2 4.9 3.0 1.4 0.2 setosa 3 4.7 3.2 1.3 0.2 setosa 4 4.6 3.1 1.5 0.2 setosa 5 5.0 3.6 1.4 0.2 setosa 6 5.4 3.9 1.7 0.4 setosa
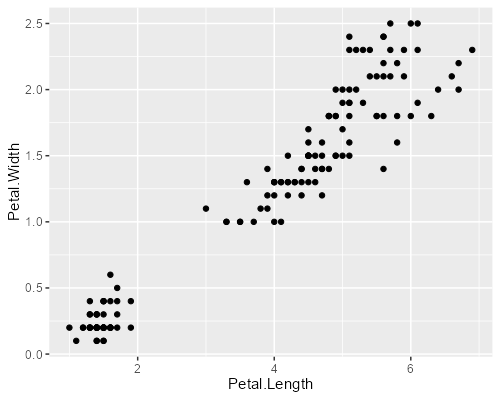
ふつうにプロットするとこんな感じです。
ggplot(iris, aes(Petal.Length, Petal.Width)) + geom_point()
geom_mark_rect
4つの関数は基本的に使い方は同じなので、geom_mark_rect を代表として使い方をざっと見ていきましょう。
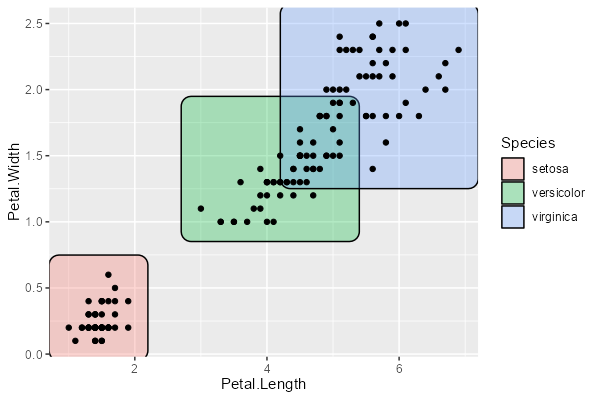
geom_mark_rect は、注目させたい領域を四角で囲む geom です。
ggplot(iris, aes(Petal.Length, Petal.Width)) + geom_mark_rect(aes(fill = Species)) + geom_point()
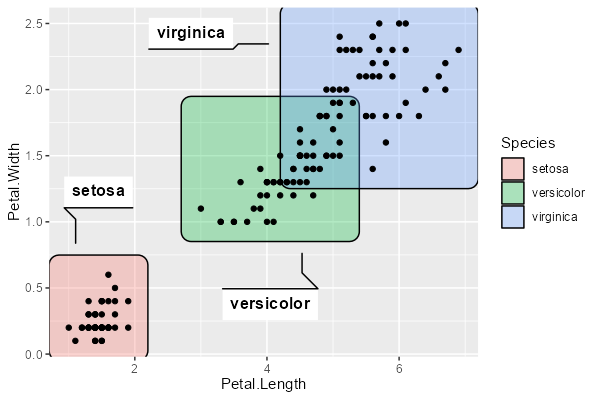
引数 label を指定することで、かっちょいいラベルを付けることができます。
ggplot(iris, aes(Petal.Length, Petal.Width)) + geom_mark_rect(aes(fill = Species, label = Species)) + geom_point()
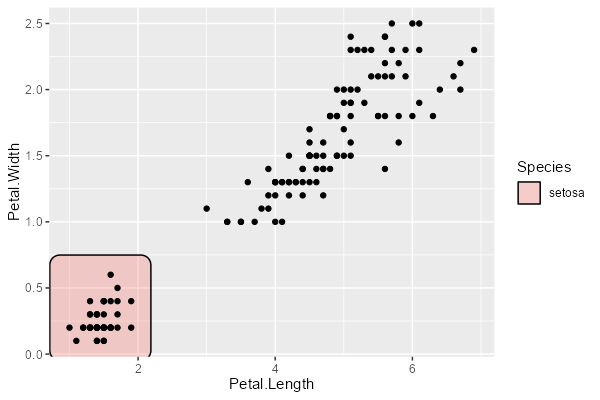
引数 filter に条件を指定することで、一部のみを強調することもできます。
これで外れ値のみを強調することができますね。
ggplot(iris, aes(Petal.Length, Petal.Width)) + geom_mark_rect(aes(fill = Species, filter = Species == "setosa")) + geom_point()
以上が基本的な使い方です。
geom_mark_circle
geom_mark_circle は、注目させたい領域を円で囲む geom です。
ggplot(iris, aes(Petal.Length, Petal.Width)) + geom_mark_circle(aes(fill = Species)) + geom_point()
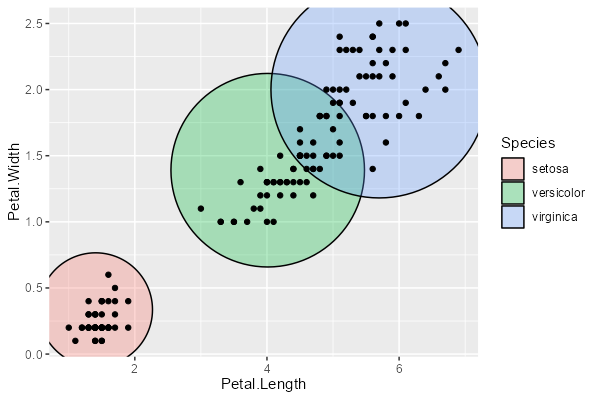
geom_mark_rect と同じく、label や filter も使えます。
geom_mark_ellipse
geom_mark_ellipse は、注目させたい領域を楕円で囲む geom です。
ggplot(iris, aes(Petal.Length, Petal.Width)) + geom_mark_ellipse(aes(fill = Species)) + geom_point()
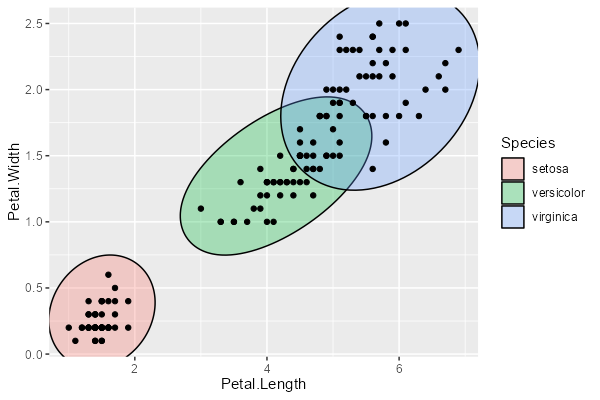
こちらも label と filter が使えます。
geom_mark_hull
geom_mark_hull は、注目させたい領域に沿った形状で囲む geom です。
この関数を使うには concaveman パッケージをインストールする必要があります。
install.packages("concaveman")
ggplot(iris, aes(Petal.Length, Petal.Width)) + geom_mark_hull(aes(fill = Species)) + geom_point()
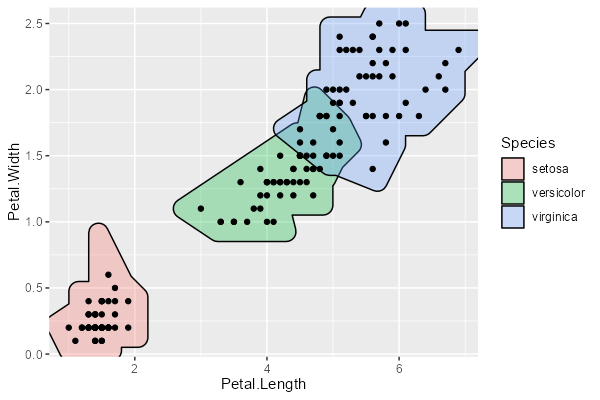
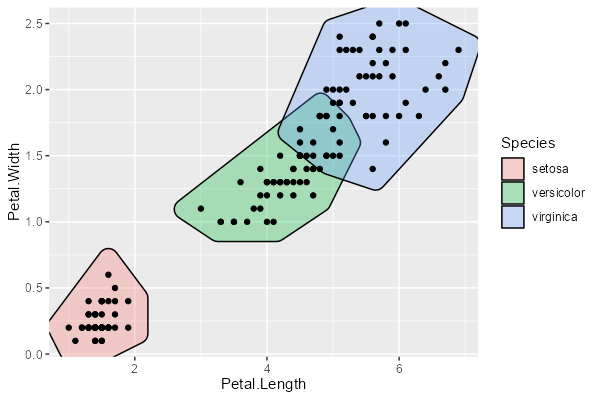
geom_mark_hull も label や filter が使えます。さらに、concavity によって、どれくらい細かく領域の形状に沿うかを指定することもできます。concavity はデフォルトは 2 で、大きくすると大雑把になります。
ggplot(iris, aes(Petal.Length, Petal.Width)) + geom_mark_hull(aes(fill = Species), concavity = 10) + geom_point()
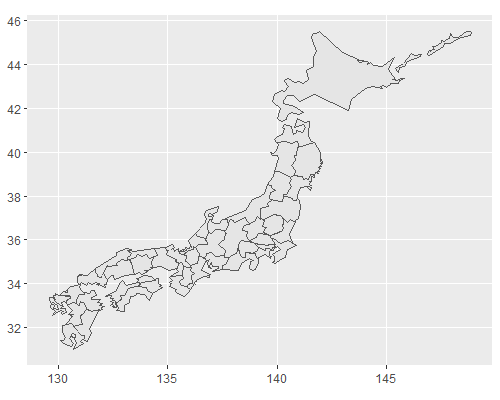
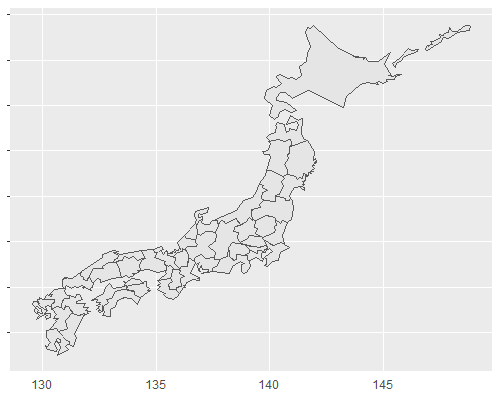
Accelerate your plots with ggforce · R Views には、geom_mark_hull 関数を地図上のプロットに使う例が載っていて良いなと思いました。
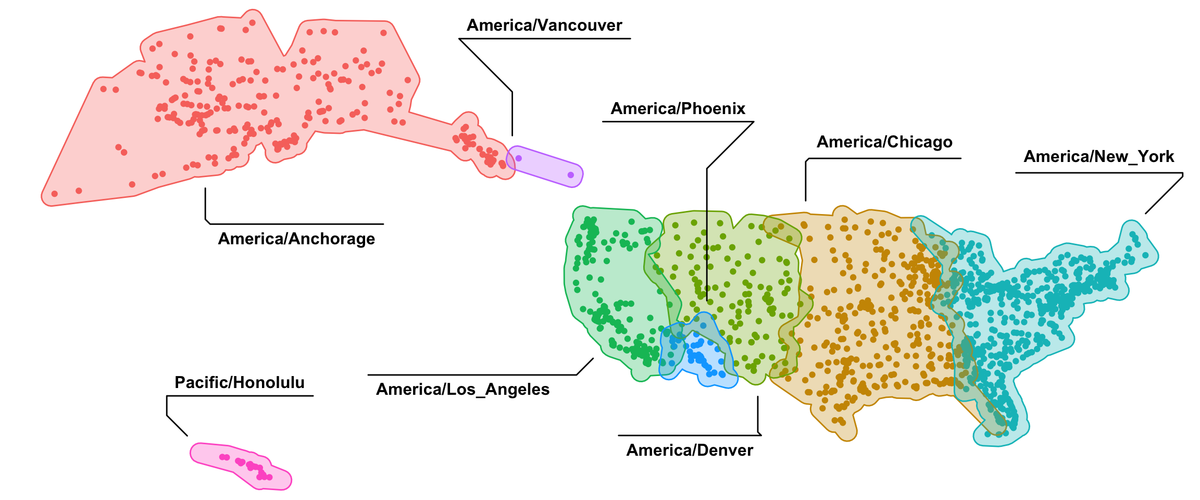
以上、ggforce パッケージの geom_mark_* 関数は便利なのでみなさんも使ってみてはどうでしょうという話でした。
enjoy!



")